diff --git a/README.md b/README.md
index 64e06cc6e..048206932 100644
--- a/README.md
+++ b/README.md
@@ -104,6 +104,7 @@ A summary can be found in the [Model Zoo](docs/en/model_zoo.md) page.
* [x] [Rotated RepPoints-OBB](configs/rotated_reppoints/README.md) (ICCV'2019)
* [x] [RoI Transformer](configs/roi_trans/README.md) (CVPR'2019)
* [x] [Gliding Vertex](configs/gliding_vertex/README.md) (TPAMI'2020)
+* [x] [CSL](configs/csl/README.md) (ECCV'2020)
* [x] [R3Det](configs/r3det/README.md) (AAAI'2021)
* [x] [S2A-Net](configs/s2anet/README.md) (TGRS'2021)
* [x] [ReDet](configs/redet/README.md) (CVPR'2021)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 4e5de4a04..e6cd17f16 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -100,6 +100,7 @@ MMRotate 也提供了其他更详细的教程:
* [x] [Rotated RepPoints-OBB](configs/rotated_reppoints/README.md) (ICCV'2019)
* [x] [RoI Transformer](configs/roi_trans/README.md) (CVPR'2019)
* [x] [Gliding Vertex](configs/gliding_vertex/README.md) (TPAMI'2020)
+* [x] [CSL](configs/csl/README.md) (ECCV'2020)
* [x] [R3Det](configs/r3det/README.md) (AAAI'2021)
* [x] [S2A-Net](configs/s2anet/README.md) (TGRS'2021)
* [x] [ReDet](configs/redet/README.md) (CVPR'2021)
diff --git a/configs/csl/README.md b/configs/csl/README.md
new file mode 100644
index 000000000..972f9dfbb
--- /dev/null
+++ b/configs/csl/README.md
@@ -0,0 +1,43 @@
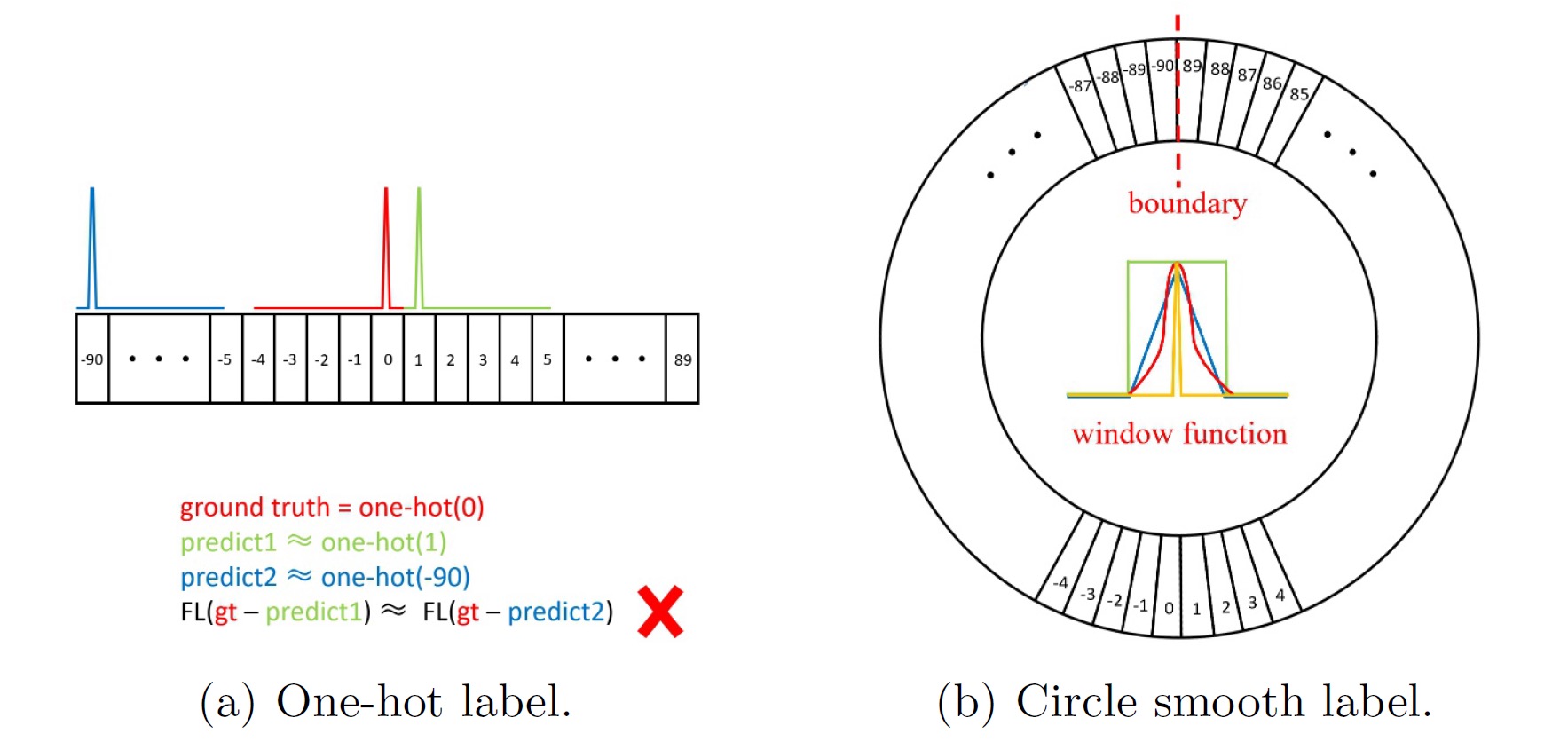
+# CSL
+> [Arbitrary-Oriented Object Detection with Circular Smooth Label](https://link.springer.com/chapter/10.1007/978-3-030-58598-3_40)
+
+
+## Abstract
+
+
+
+