Home
pip3 install flight_profilerThis command will install flight_profiler to the current Python3 site-packages directory. After installation, you can use the global command flight_profiler for debugging.
First, find the target debugging process by checking the process PID with the ps command:
ps -ef | grep pythonStart debugging by passing the target PID as a parameter:
flight_profiler pidYou can then start entering debugging commands.
View all available commands and their specific usage.
help [command]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| command | No | The command name to view | stack |

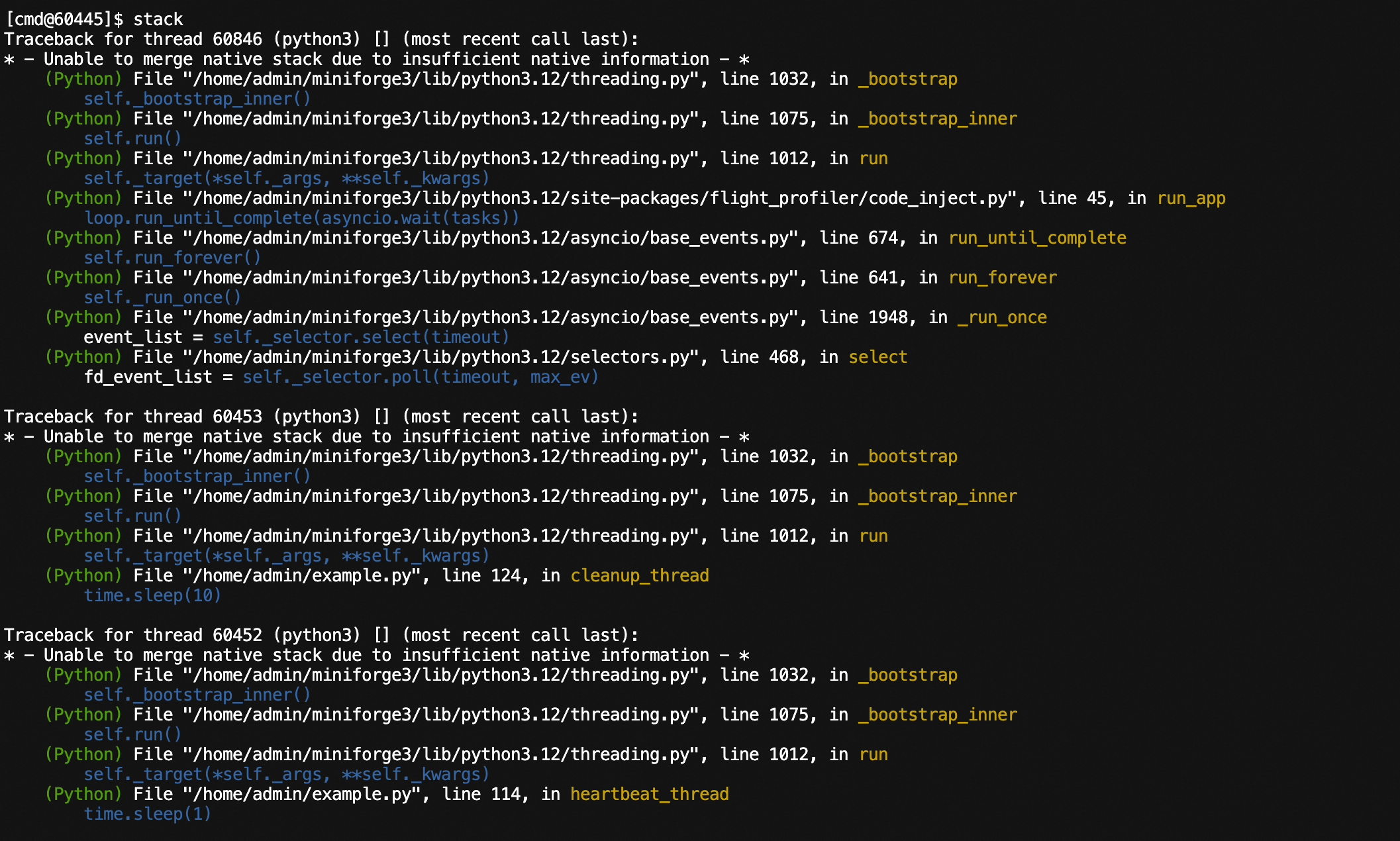
View Python execution stack information for all threads currently running in the process, and support analyzing native stacks and exporting to files.
stack [pid] [-f <value>] [--native]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| pid | No | Process ID to analyze, defaults to the injected process ID | 3303 |
| -f, --filepath | No | File path to export thread stacks to | /home/admin/stack.log |
| --native | No | Whether to analyze native stacks of Python threads, defaults to False | --native |
Command examples:
# View Python thread stacks
stack
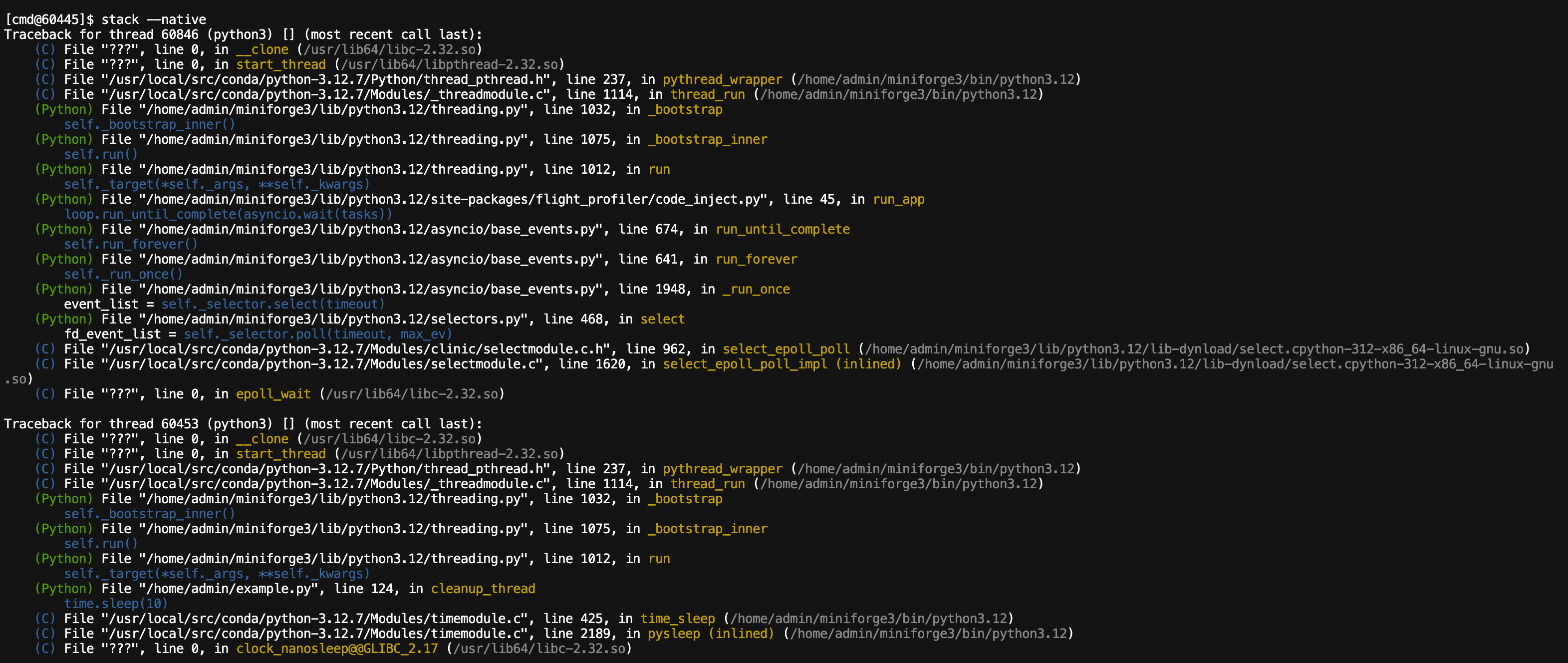
# View native stacks of Python threads
stack --native
# Export execution stack information to a file
stack -f ./stack.logExecuting the stack command will display stack information for all threads in the console.
Analyzing native thread stacks:
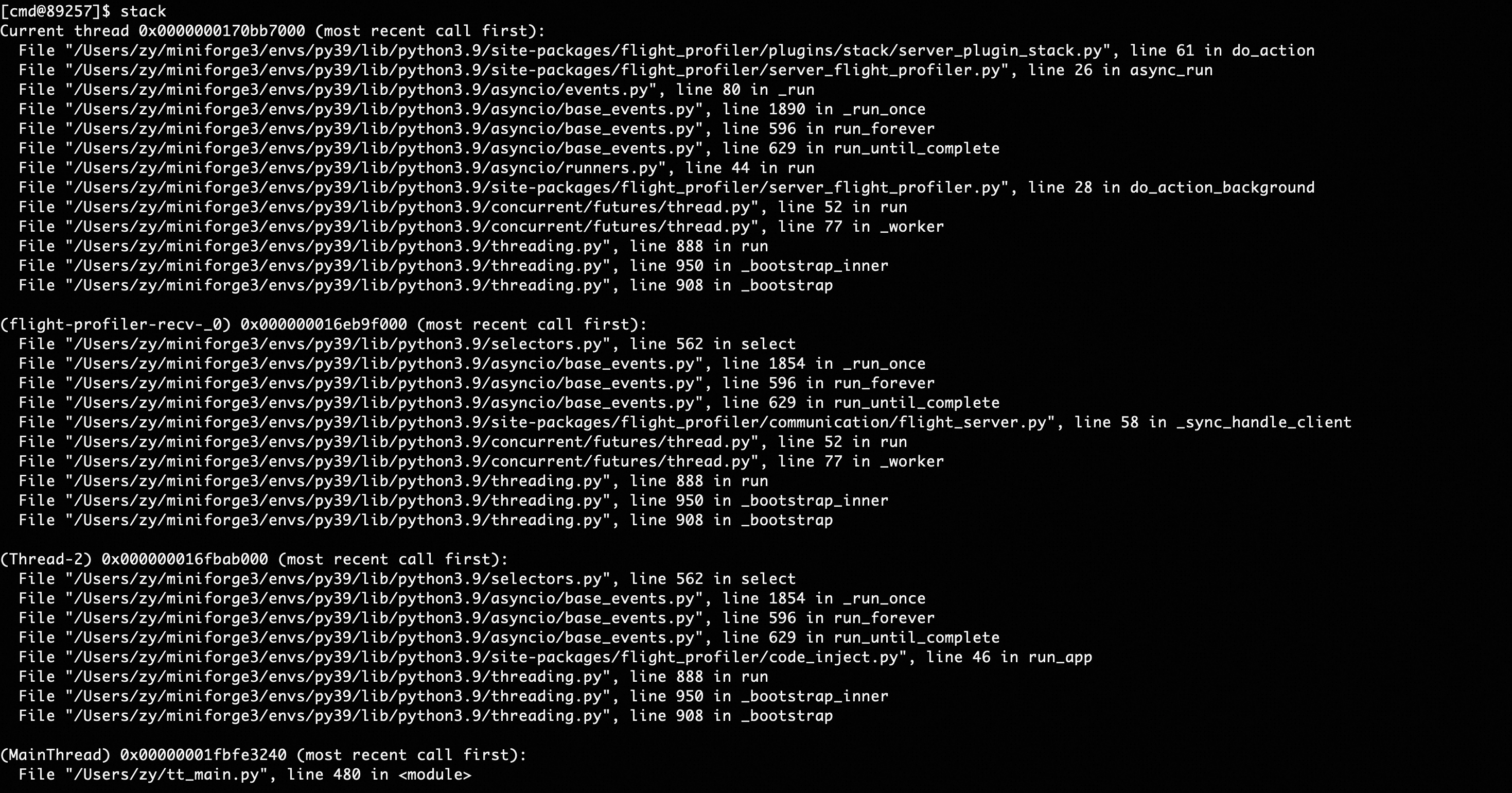
View Python execution stack information for all threads currently running in the process, and support exporting to files.
stack [filepath]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| filepath | No | File path to export thread stacks to | /home/admin/stack.log |
Executing the stack command will display stack information for all threads in the console.
The watch command is as follows:
watch module [class] method [--expr <value>] [-nm <value] [-e] [-r] [-v] [-n <value>] [-x <value>] [-f <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| module | Yes | Module where the method is located | main, my.pkg.modulename |
| class | No | Class name where the method is located | className |
| method | Yes | Method name to observe | methodName |
| -nm, --nested-method | No | Whether capture nested method with depth restrict to 1 | -nm nested_method |
| --expr | No | Expression to observe. Reference Python method parameters as (target, return_obj, cost, *args, **kwargs), where target is the class instance (if the call is a class method), return_obj is the method return object, cost is the method call time consumption, *args are non-specified parameters, and **kwargs are specified parameters. Need to return a right-value expression about these parameters. Defaults to args, kwargs |
--expr args,kwargs,return_obj |
| -e | No | exception, only record when method execution has an exception | -e |
| -r, --raw | No | Whether to directly display the string representation of the target | -r |
| -v, --verbose | No | Whether to display all sub-items of target lists/dictionaries | -v |
| -x, --expand | No | expand, depth to display observed objects, defaults to 1, maximum is 4 | -x 2 |
| -f, --filter | No | Filter parameter expression, only calls passing the filter conditions will be observed. Writing format is the same as --expr directive, needs to return a boolean expression. |
-f args[0]["query"]=='hello' |
| -n, --limits | No | Maximum number of observed display items, defaults to 10 | -n 50 |
Expression Notes:
- If the expression value contains spaces, it needs to be enclosed in quotes, for example -f "args[0] == 'hello'"
- If the observed value contains class instances, for private variables in class instances (fields starting with __), users need to explicitly modify the access method. For example, if args[0] is an instance of class A containing a __val variable, the expression should be: --expr args[0]._A__val, which adds the "_class_name" prefix before the private variable (Python convention)
Command examples:
# watch module function
watch __main__ func -x 2
# watch module function and filter parameters
watch __main__ func -f "args[0][\"query\"]=='hello'"
# watch module function and filter return values
watch __main__ func -f "return_obj['success']==True"
# watch module function and filter function call time consumption
watch __main__ func --expr "{return_obj,args}" -f "cost>10"
# watch class function
watch __main__ classA func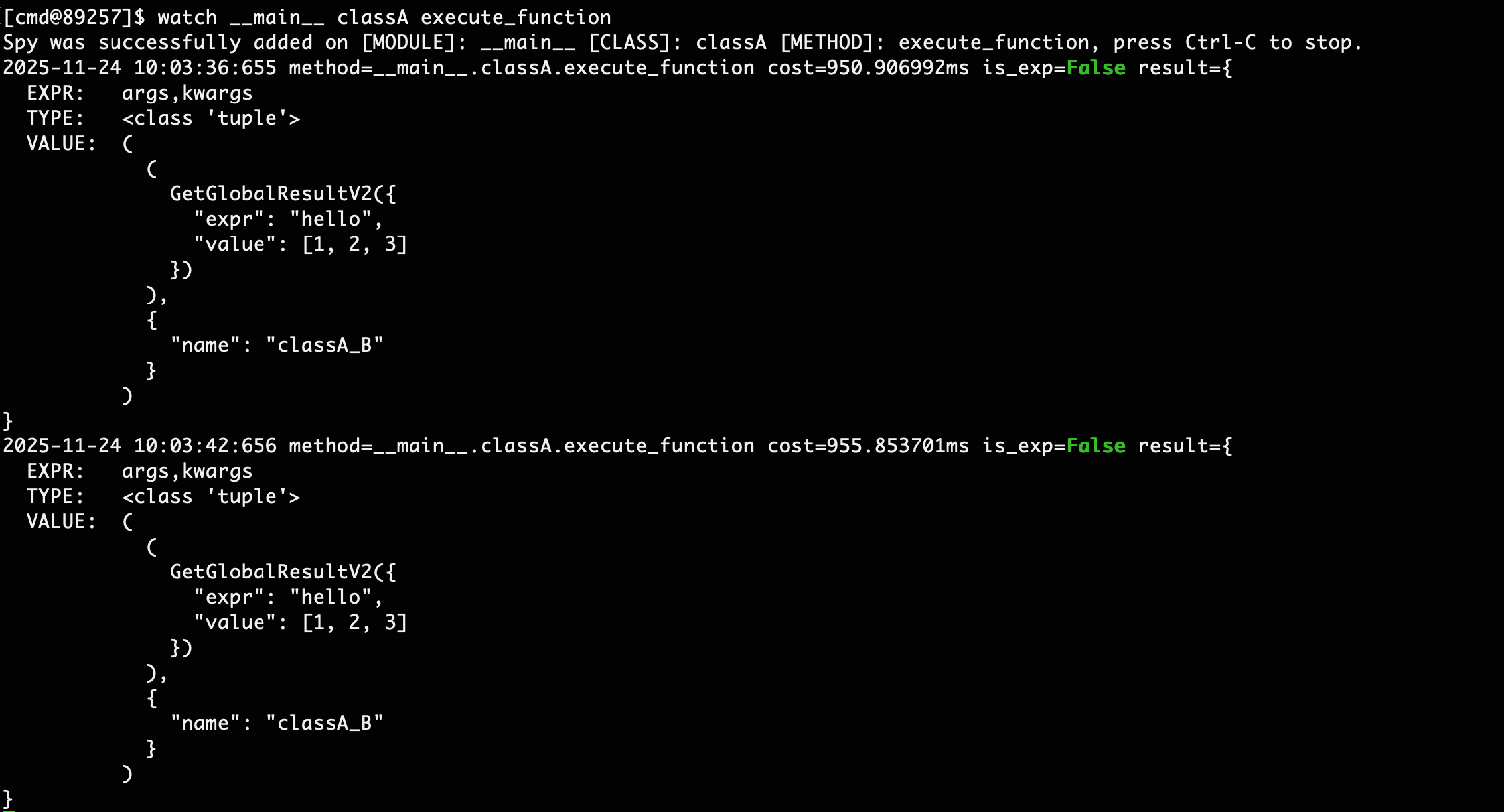
Output field information includes:
- cost: Method execution time consumption, in milliseconds
- result: Observation results item by item for the watch command expression
- EXPR: Expression name, such as arg for positional parameters, kwargs for keyword parameters
- VALUE: Expression value, such as arg expression displayed as parameter list, kwargs expression displayed as key-value pairs
The trace command is as follows:
trace module [class] method [-i <value>] [-nm <value>] [-et <value>] [-d <value>] [-n <value>] [-f <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| module | Yes | Module where the method is located | main, my.pkg.modulename |
| class | No | Class name where the method is located | className |
| method | Yes | Method name to observe | methodName |
| -nm, --nested-method | No | Whether capture nested method with depth restrict to 1 | -nm nested_method |
| -d, --depth | No | Display the method call stack, limited to the specified depth ${value}. When a depth is specified, the ${interval} parameter is ignored and its value is constrained to 0. | -d 3 |
| -i, --interval | No | Only observe internal method calls with execution time greater than #{interval}, defaults to 0.1ms. Note that the smaller #{interval} is, the greater the observation overhead on method execution. Tested overhead for simple text reasoning methods is about 10%~20% under default conditions, fluctuating with the complexity of the observed method. | -i 1 |
| -et, --entrance_time | No | Only display method calls with execution time exceeding #{entrance_time} | -et 30 |
| -f, --filter | No | Filter parameter expression, only calls passing filter conditions will be observed. Reference Python method parameters as (target, *args, **kwargs), needs to return a boolean expression about target, args, and kwargs, where target is the class instance (if the call is a class method), args and kwargs are the called method's parameters |
-f "args[0]["query"]=='hello'" |
| -n, --limits | No | Maximum number of observed display items, defaults to 10 | -n 50 |
Command examples:
# Trace module function
trace __main__ func
# Trace module function and only trace function calls with execution time exceeding 1ms
trace __main__ func -i 1
# Trace class function
trace __main__ classA func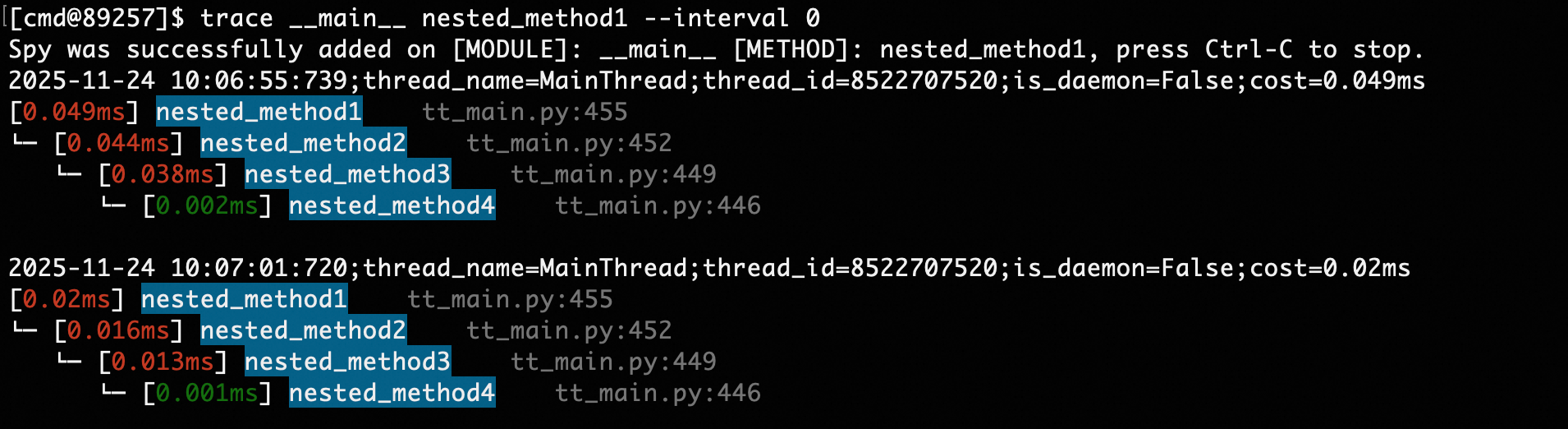
The tt command is as follows:
tt [-t module [class] method] [-n <value>] [-l] [-i <value>] [-d <value>] [-da] [-x <value>] [-p] [-f <value>] [-r] [-v] [-m <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| -t module [class] method | No | Observe method calls in the specified module over time and space, module/class/method definitions are the same as in watch/trace | -t moduleA classA func |
| -nm, --nested-method | No | Whether capture nested method with depth restrict to 1 | -nm nested_method |
| -n, --limits | No | Maximum number of observed display items, defaults to 50 | -n 50 |
| -l, --list | No | Display all method call segments | -l |
| -i, --index | No | Display details of the method call corresponding to the index | -i 1000 |
| -d, --delete | No | Delete the call record corresponding to the index | -d 1000 |
| -da, --delete_all | No | Delete all call records | -da |
| -r, --raw | No | Whether to directly display the string representation of the target, i.e., repr(target) | -r |
| -v, --verbose | No | Whether to display all sub-items of target lists/dictionaries | -v |
| -x, --expand | No | expand, depth to display observed objects, defaults to 1, maximum is 4 | -x 2 |
| -p, --play | No | Whether to re-trigger historical calls, used with -i, using the call parameters specified by index | -i 1000 -p |
| -f, --filter | No | Filter parameter expression, reference watch command | -f "args[0]["query"]=='hello'" |
| -m, --method | No | Filter method name, format is module.class.method, if the method is a class method, class is None, compatible with -l | -l -m moduleA.classA.methodA |
Command examples:
# Record module method
tt -t __main__ func
# Record class method
tt -t __main__ A func
# Display called method record list
tt -l
# Display specified call details
tt -i 1000 -x 3
# Re-trigger the call with index 1000, using the same input
tt -i 1000 -p
# Only observe records with return value 'success' and time consumption greater than 10ms
tt -t __main__ func -f "return_obj['success']==True and cost>10"
# Only observe requests where the first method parameter contains a query field with value "hello"
tt -t __main__ func -f "args[0][\"query\"]=='hello'"Observing method calls:
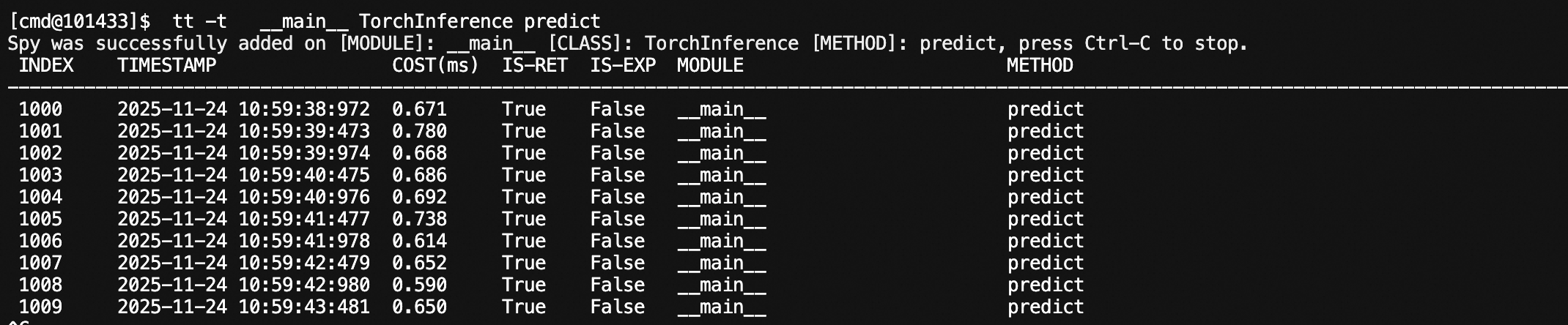
Specifying index:
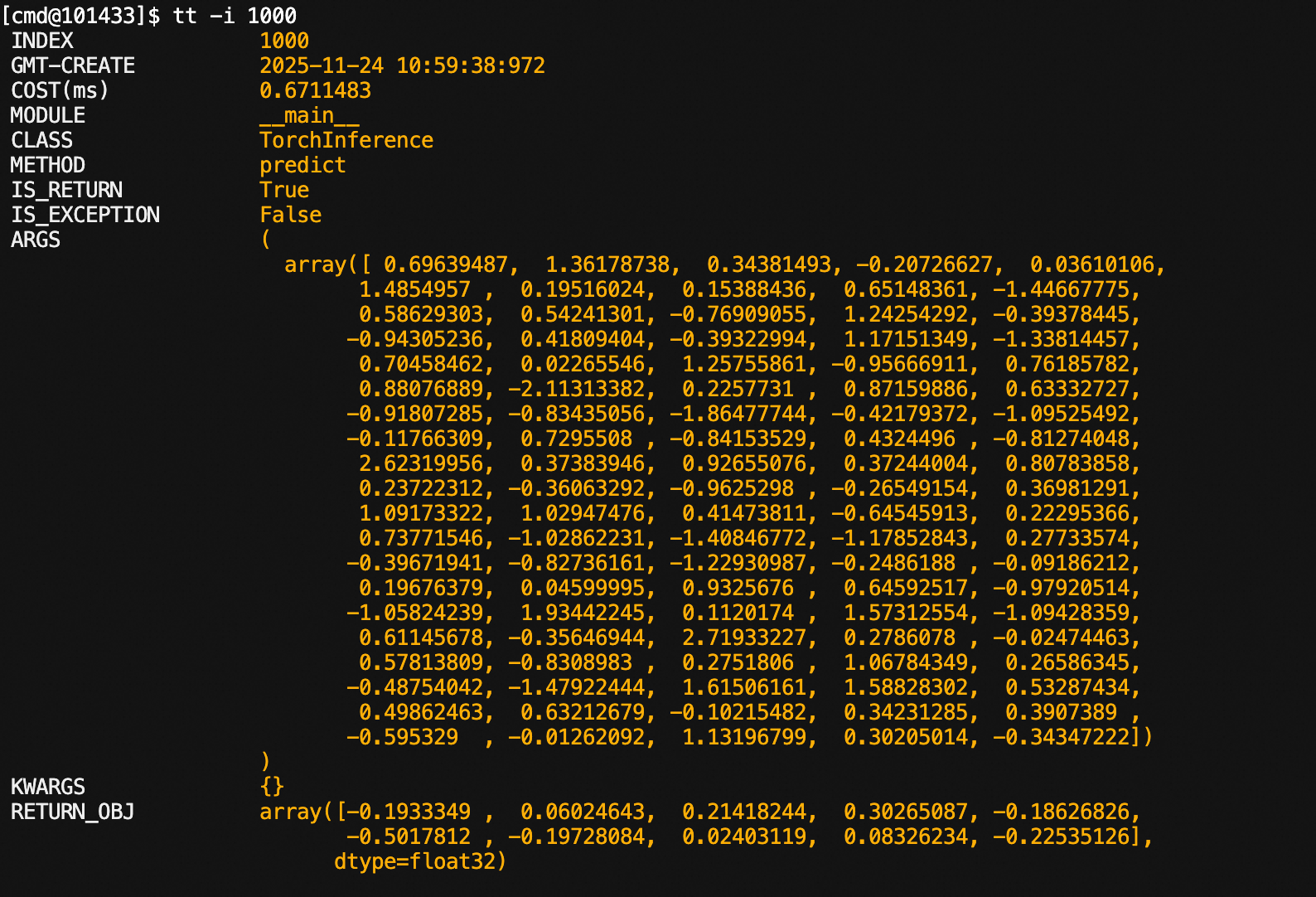
Re-executing historical calls:
It can be seen that the index has changed: 1000 -> 1010
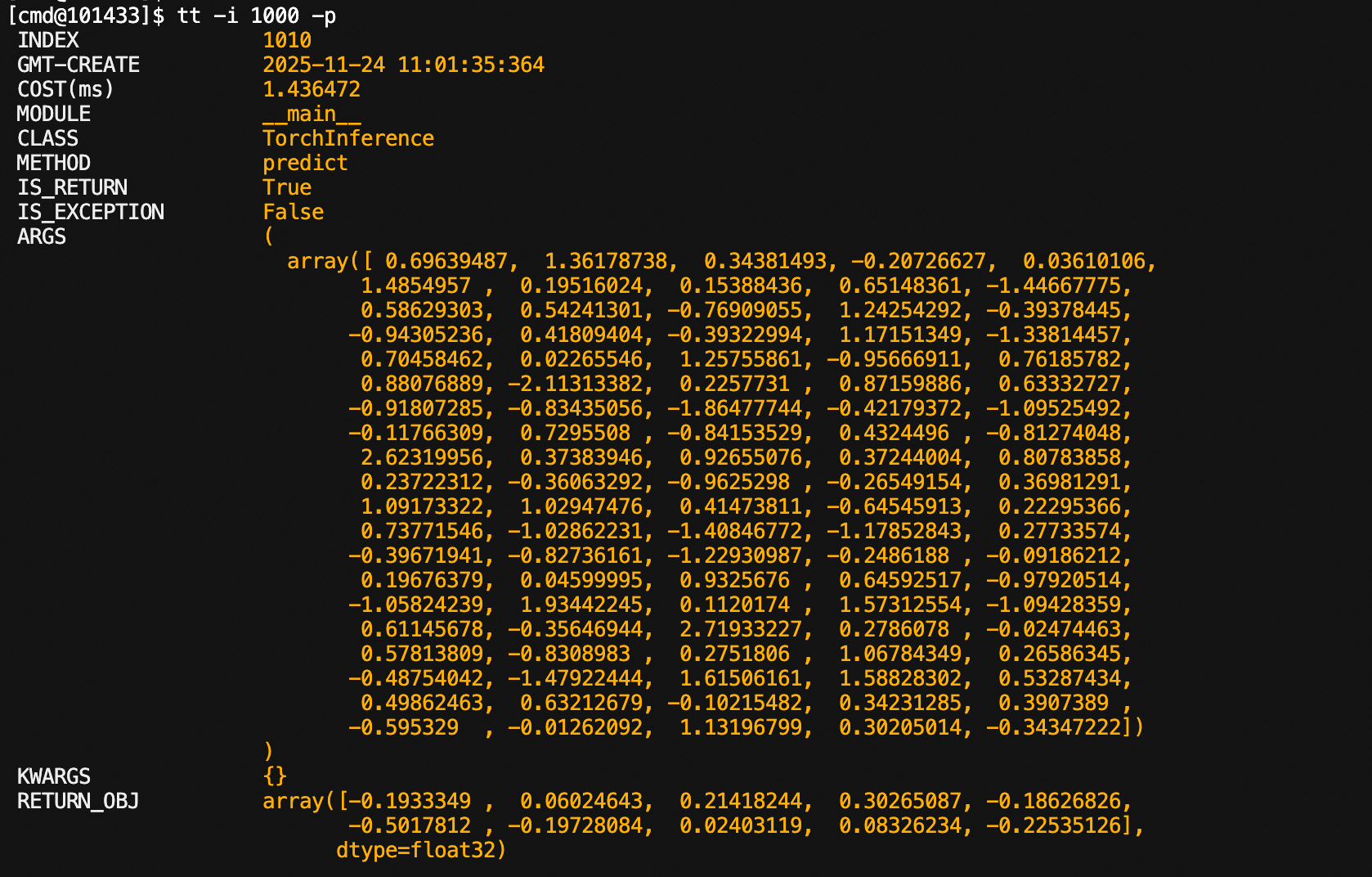
The getglobal command is as follows:
getglobal module [class] field [-x <value>] [-e <value>] [-r] [-v]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| module | Yes | Module where the field is located | main, my.pkg.modulename |
| class | No | Class name where the field is located | className |
| field | Yes | Field name | fieldName |
| -e, --expr | No | Expression for observing objects, reference Python method parameters as (target), target is the observed object, needs to return a right-value expression about target. | -e target.fieldA |
| -x, --expand | No | expand, depth to display observed objects, defaults to 1, maximum is 4 | -x 2 |
| -r, --raw | No | Whether to directly display the string representation of the target | -r |
| -v, --verbose | No | Whether to display all sub-items of target lists/dictionaries | -v |
For variables in python files started by main, use the following command:
# Module variables
getglobal __main__ g_list
# Class static variables
getglobal __main__ classA static_field
Command as follows:
vmtool -a getInstances -c module class [-e <value>] [-x <value>] [-n <value>] [-v] [-r]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| module | Yes | Module where the class is located | main, my.pkg.modulename |
| class | Yes | Class name | className |
| -e, --expr | No | Expression for observing objects, reference Python method parameters as (instances), instances is the instance list of the corresponding class, needs to return a right-value expression about instances. | -e instances[0].fieldA |
| -x, --expand | No | expand, depth to display observed objects, defaults to 1, maximum is 4 | -x 2 |
| -r, --raw | No | Whether to directly display the string representation of the target | -r |
| -v, --verbose | No | Whether to display all sub-items of target lists/dictionaries | -v |
| -n, --limits | No | Control the number of displayed instances, defaults to 10, -1 means no limit | -n 1 |
For variables in python files started by main, use the following command:
# View all instances of class A
vmtool -a getInstances -c __main__ A
# View variables of instances of class A
vmtool -a getInstances -c __main__ A -e instances[0].val
Command as follows:
vmtool -a forceGcvmtool -a forceGc
This command will output the module corresponding to the filename in the injected process, facilitating users to directly locate methods or variables based on exception stacks.
The module command is as follows:
module filepath| Parameter | Required | Meaning | Example |
|---|---|---|---|
| filepath | Yes | Filename to be escaped | /home/admin/main.py |
Command examples:
# Corresponding module is __main__.py
module ~/tt_main.py
# Not imported into the specified process
module ~/not_exist.py

Sample profile the program process to generate flame graphs, facilitating users to optimize program hotspots, implemented based on py-spy.
The perf command:
perf [pid] [-f <value>] [-r <value>] [-d <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| [pid] | No | Process ID to analyze, defaults to the injected process | 123/empty |
| -f, --filepath | No | Path to export flame graph, defaults to flamegraph.svg in current directory | -f ~/sample.svg |
| -r --rate | No | Samples per second, defaults to 100 | -r 1000 |
| -d --duration | No | Duration in seconds, defaults to waiting for user interruption | -d 30 |
Command examples:
perf
# Output will be exported to ~/flamegraph.svg
perf -f ~/flamegraph.svg
# Sample for 30s
perf -d 30 -f ~/flamegraph.svgUsing this command on MacOS requires root permissions for py-spy

Enable interactive console in the specified process, supporting users to execute custom scripts, get system properties, and other operations.
The console command:
consoleCommand examples:
console
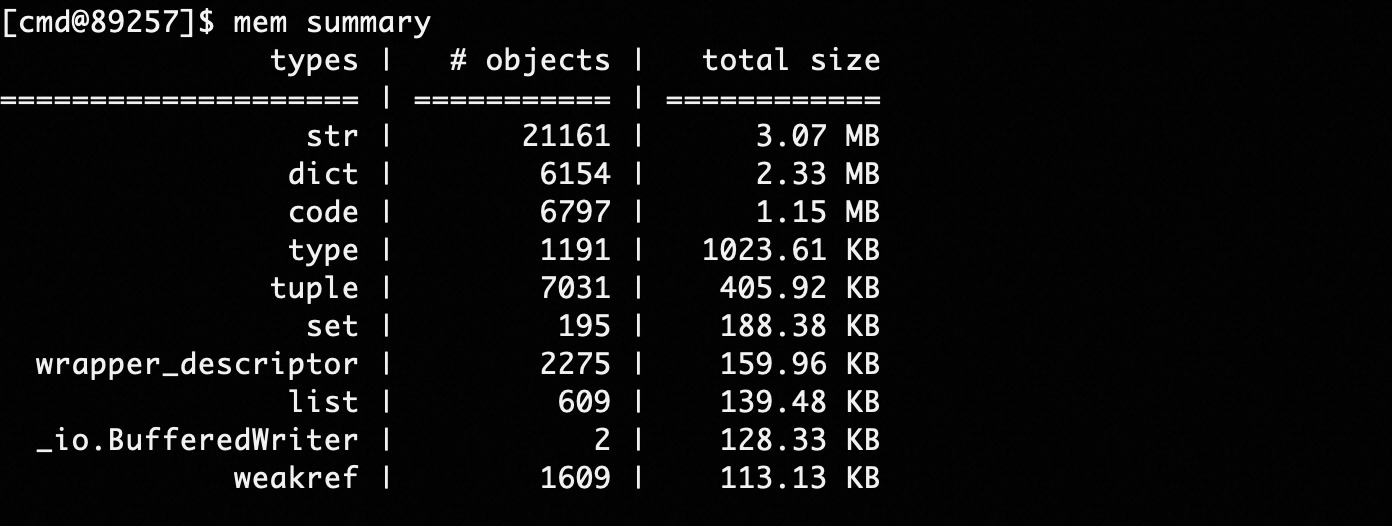
The summary command can statistically analyze memory usage by variable type:
mem summarymem summary --limit 100 --order descendingWhere the limit parameter controls the number of TOP items displayed, and order controls sorting in descending or ascending order (descending/ascending).
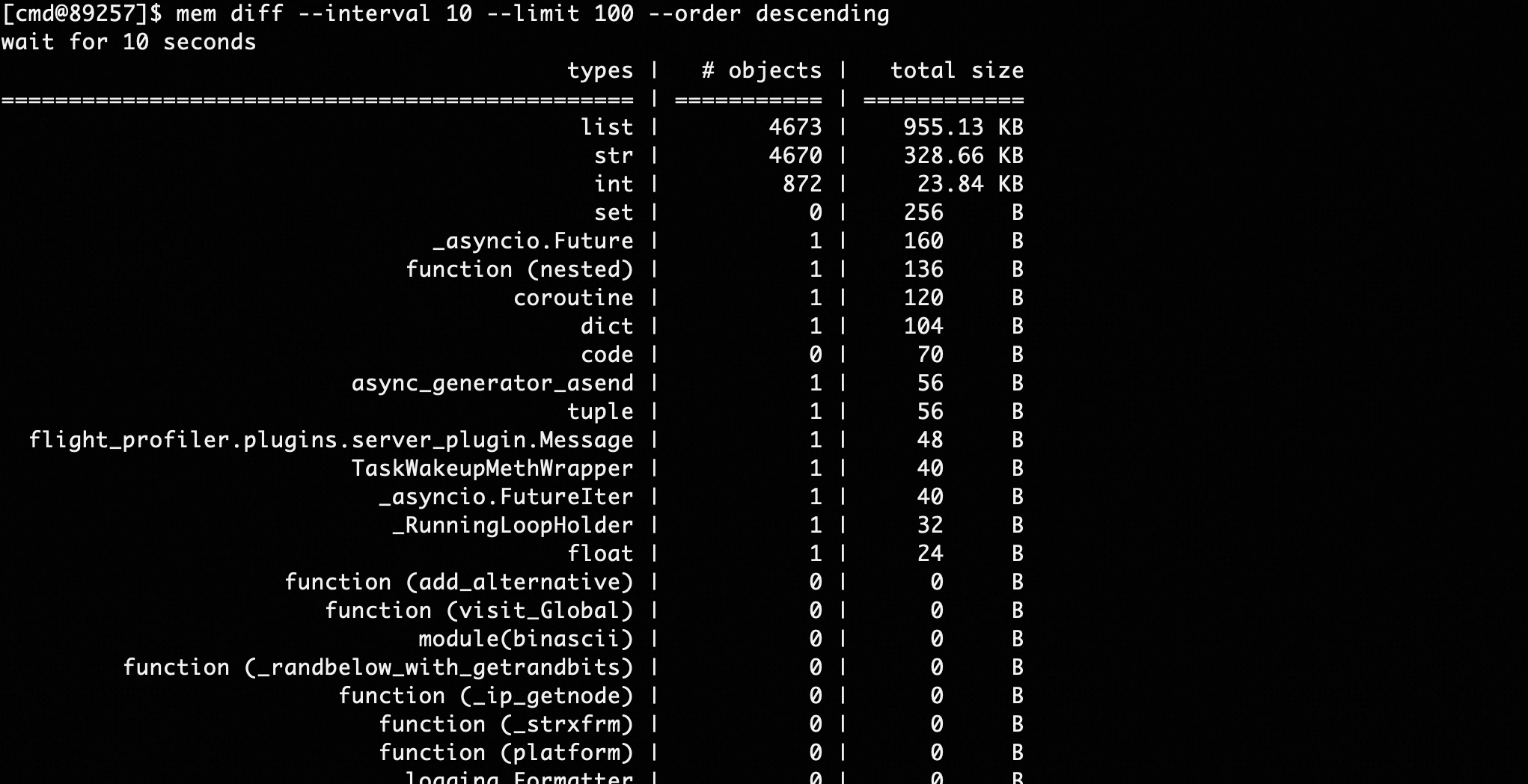
This command can compare memory size differences between two time points:
mem diff --interval 10 --limit 100 --order descendingAs shown in the above command, take memory snapshots before and after 10s, compare differences, and display memory variable types with the largest differences in descending order, as shown below:
gilstat onAfter executing the gilstat on command, the console will output GIL lock loss statistics for each thread every 5 seconds.

Output information fields include:
- thread_name: Thread name
- takecnt: Cumulative number of times GIL lock was acquired
- hold_all: Cumulative time holding GIL lock, in nanoseconds, 1ms = 1000000ns
- holdavg: Average time holding GIL lock after successfully acquiring it each time. When holding the GIL lock, other threads will pause execution, which can cause P99 to increase. Performance optimization tip: This value can reflect whether the thread is computationally overloaded, and you might consider reducing continuous CPU computation time and appropriately yielding time slices to other threads.
- take_all: Cumulative wait time for acquiring GIL lock, as only one thread can acquire the GIL lock, other threads need to wait when taking the GIL lock. This can be understood as the time threads are blocked waiting for a mutex lock.
- takeavg: Average wait time for acquiring GIL lock
- drogcnt: Cumulative number of times GIL lock was released, usually equal to takecnt
- drog_all: Cumulative time consumed releasing GIL lock, usually very small
- dropavg: Average wait time for releasing GIL lock
gilstat on 5 5The first parameter 5 represents the GIL lock acquisition time threshold of 5ms and the GIL lock holding time threshold of 5ms. That is, when a thread's GIL lock acquisition blocking exceeds 5ms, or a thread's GIL lock holding time exceeds 5ms, a monitoring message will be printed. This command can analyze some long-tail timeout queries in production.

Implemented based on Torch Profiler, able to sample time consumption of execution functions in the torch framework, and execution on CPU or GPU.
Command examples:
torch profile module [class] method [-f <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| module | Yes | Module where the method is located | main, my.pkg.modulename |
| class | No | Class name where the method is located | className |
| method | Yes | Method name to observe | methodName |
| -nm, --nested-method | No | Whether capture nested method with depth restrict to 1 | -nm nested_method |
| -f --filepath | No | File path to export sampling files to, defaults to trace.json in current directory | -f ~/trace.json |
Command examples:
# Sample the hello method of class A in the __main__ module
torch profile __main__ A hello
The generated trace.json file needs to be placed in the chrome://tracing/ path of the Chrome browser for visualization, as shown in the result below
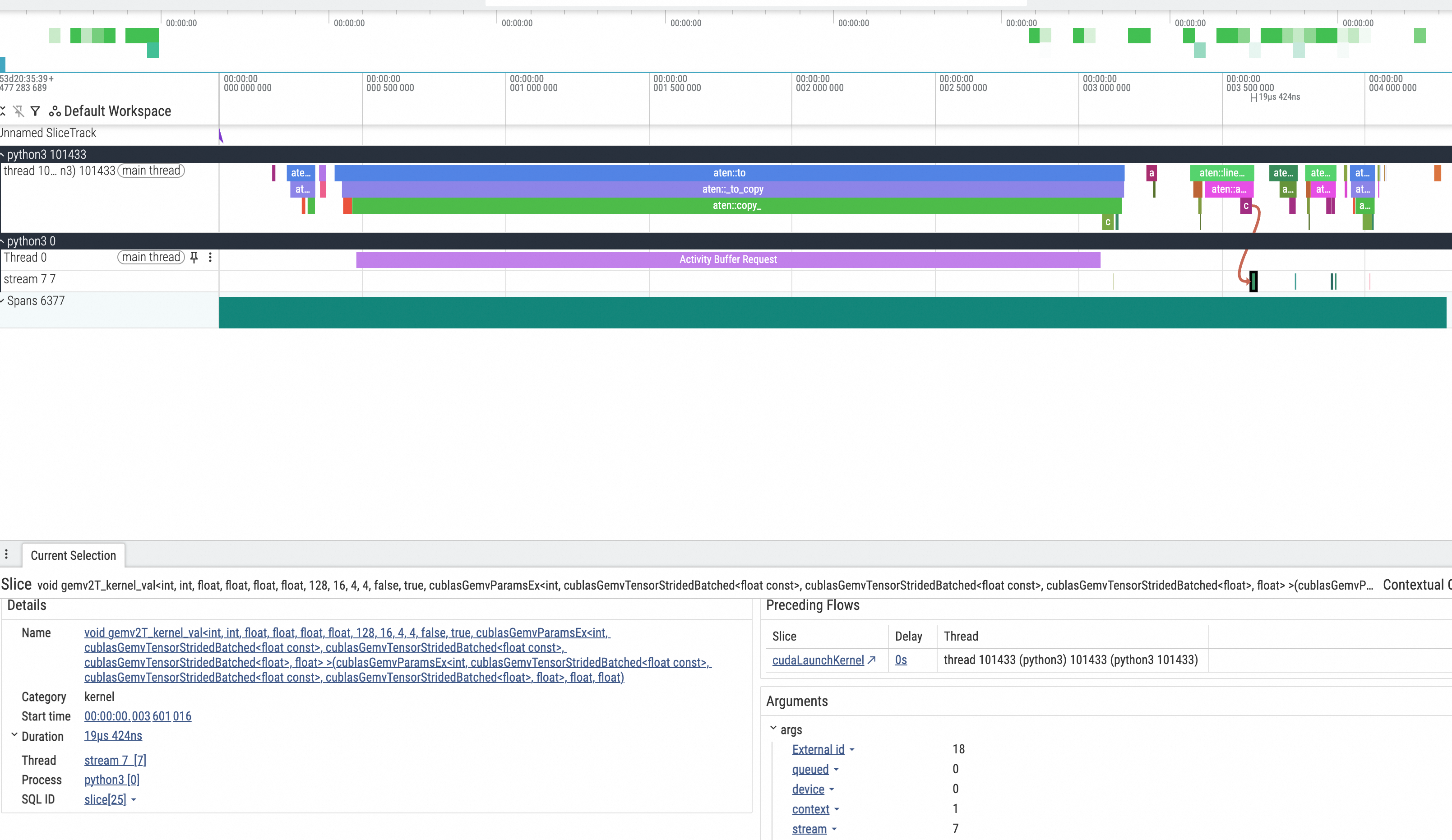
Implemented based on Torch Profiler, able to snapshot memory space used by the process, or record memory allocation behavior during method execution:
torch memory [-s] [-r module [class] method] [-f <value>]| Parameter | Required | Meaning | Example |
|---|---|---|---|
| -s, --snapshot | No | Whether to snapshot the memory space used by the current process | -s |
| -r, --record | No (choose one of -s, -r) | Whether to record torch framework memory allocation actions during method execution, module, class, method consistent with profile | -r module class |
| -nm, --nested-method | No | Whether capture nested method with depth restrict to 1 | -nm nested_method |
| -f --filepath | No | File path to export sampling files to, defaults to snapshot.pickle in current directory | -f ~/snapshot.pickle |
Command examples:
# Snapshot the torch memory used by the current process
# Due to torch monitoring memory
torch memory -s
# Observe memory allocation actions during method execution
torch memory -r __main__ Solution callThe generated snapshot.pickle file needs to be analyzed in https://pytorch.org/memory_viz, as shown in the result below, where the left list shows the timing behavior of allocation and collection:
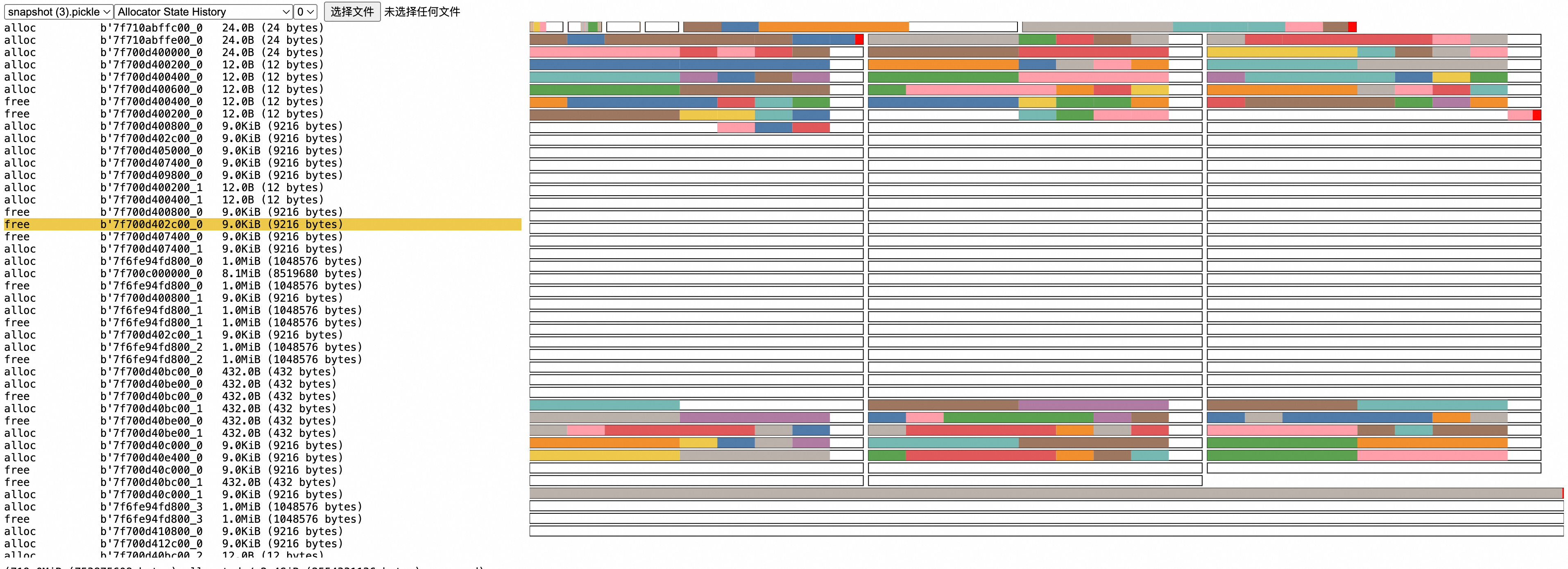
For specific principles/how to get effective information from the graph: https://pytorch.org/docs/2.5/torch_cuda_memory.html
Note:
Since sampling of historical memory allocation under the torch framework has not been enabled, stack information cannot be traced for already allocated memory. If you want to see allocation behavior from program startup (usually in development environment), you can use the following methods:
- Delay major memory allocation to a method, then use record to record method execution
- Add a small script before the program starts to indicate enabling sampling
-
For 2.0.0 <= torch < 2.1.0 versions, add at program start, then use snapshot command to view
from torch.cuda.memory import _record_memory_history _record_memory_history(enabled=True, trace_alloc_max_entries=100_000, trace_alloc_record_context=True)
-
For torch >= 2.1.0 versions, add at program start
from torch.cuda.memory import _record_memory_history _record_memory_history()
-