Conversation
Codecov Report
@@ Coverage Diff @@
## main #4156 +/- ##
=======================================
+ Coverage 99.7% 99.7% +0.1%
=======================================
Files 349 349
Lines 37809 38094 +285
=======================================
+ Hits 37692 37977 +285
Misses 117 117
|
| self.data_splitter = data_splitter | ||
| self.optimize_thresholds = optimize_thresholds | ||
| self.ensembling = ensembling | ||
| if objective == "auto": |
There was a problem hiding this comment.
This section was not deleted, simply moved down lower to be part of the other objective handling. It needed to be lower rather than moving the new handling up here because the new recommendation_objective logic requires several other validation checks to have already happened and self.X_train and self.y_train to be set.
 jeremyliweishih
left a comment
jeremyliweishih
left a comment
There was a problem hiding this comment.
Overall LGTM - great work! Just have some nits and you may need to take a look at the docs for the new rankings!
| ] | ||
|
|
||
| if problem_type == ProblemTypes.MULTICLASS and imbalanced: | ||
| objective_list.remove(objectives.AUCMicro.name) |
There was a problem hiding this comment.
do you think it would be more clear to define lists for every problem type instead of encoding it in logic? I'm not too sure about this but just a thought.
There was a problem hiding this comment.
Yeah, I went back and forth on this a lot. I figured this was more concise, but it may also be more unclear. I'm happy to change this around if need be!
docs/source/user_guide/automl.ipynb
Outdated
| ")\n", | ||
| "automl_recommendation.search(interactive_plot=False)\n", | ||
| "\n", | ||
| "automl_recommendation.rankings" |
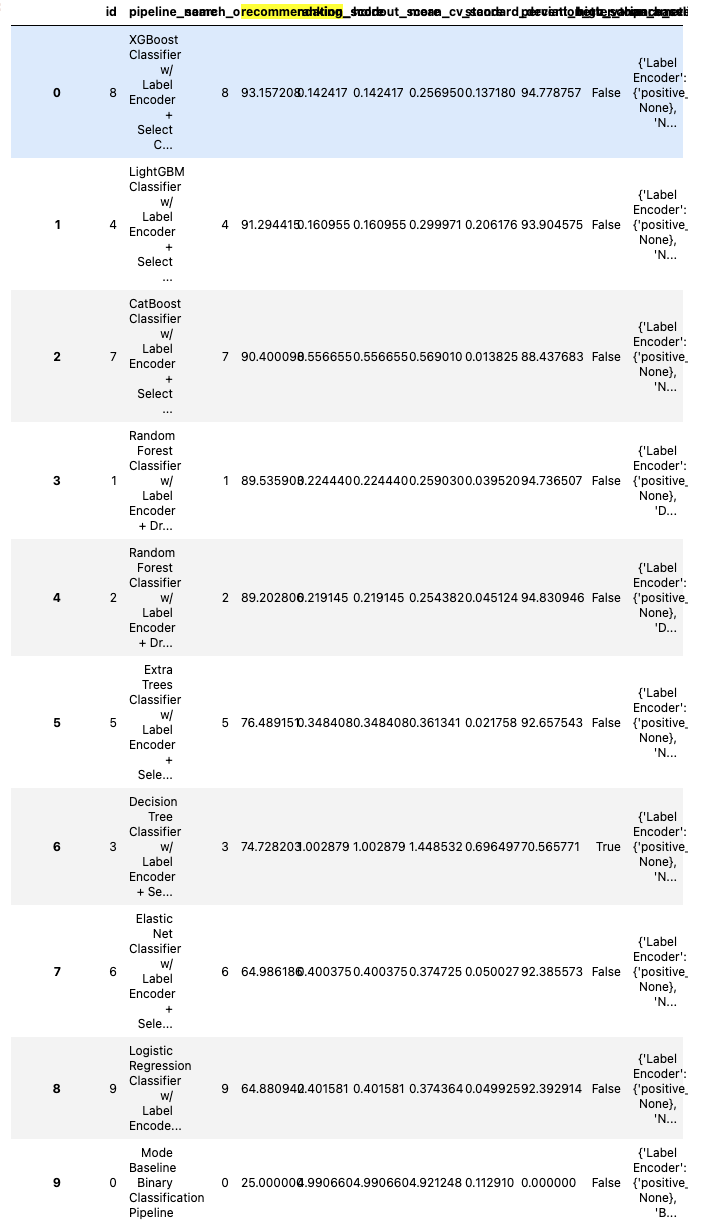
There was a problem hiding this comment.
This is a weird one. It doesn't happen when running the jupyter notebooks directly, and it looks like the same issue comes up with other rankings dataframes as well - this one looks the worst since it has the most columns. I think I'll drop some unnecessary columns so that they aren't so squished, but I'm also open to other suggestions, as Google was unhelpful here.
| if prioritized_objective is not None: | ||
| if prioritized_objective not in objectives: |
There was a problem hiding this comment.
prioritized_objective allows us to give more (or I guess less) weight to a single objective. Is it worth designing this function such that it accepts instead an objectives_weighting (dict[str,float]): Mapping of objectives to their relative weighting to compose the recommendation score ?
I was kind of thinking that there would existing presets that would function as data scientist selected "blends" of metrics based on what our user was looking for. This would require weighting of multiple metrics at the same time.
There was a problem hiding this comment.
That was my original design - amended after discussion here
| assert "already one of the default objectives" in caplog.text | ||
|
|
||
|
|
||
| def test_recommendation_include_non_optimization(X_y_binary): |
There was a problem hiding this comment.
What's this test about?
There was a problem hiding this comment.
We get the additional (not main objective) scores through the additional_objectives mechanism. By default, this calculates the objectives for all of the optimization metrics, excluding any that are classified as ranking only (and we have a check against it). However, we want to make sure users have full control over which objectives are included in the recommendation score - including ones that are ranking only (for example, recall). This test ensures that the logic permitting this works
|
|
||
|
|
||
| @pytest.mark.parametrize("imbalanced_data", [True, False]) | ||
| def test_use_recommendation_score_imbalanced( |
There was a problem hiding this comment.
I reviewed the code...why are we treating imbalanced data differently?
There was a problem hiding this comment.
This was discussed in the design doc - it's exclusively used in the multiclass classification case, when selecting whether to use AUC Micro or AUC weighted, because micro averages are better for imbalanced datasets.
| ranking_column = "ranking_score" | ||
| if self.use_recommendation: |
There was a problem hiding this comment.
Is there any benefit to modifying the API of full_rankings() to have the ranking column be selectable via the function call rather than the AutoML init setting? Probably not, I guess. Wouldn't want the user to be able to select "recommendation_score" with self.use_recommendation not having been set...
evalml/objectives/utils.py
Outdated
| prioritized_objective (str): An optional name of a priority objective that should be given heavier weight | ||
| than the other objectives contributing to the score. Defaults to None, where all objectives are | ||
| weighted equally. | ||
| prioritized_weight (float): The weight (maximum of 1) to attribute to the prioritized objective, if it exists. | ||
| Should be between 0 and 1. Defaults to 0.5. | ||
| custom_weights (dict[str,float]): A dictionary mapping objective names to corresponding weights between 0 and 1. | ||
| If all objectives are listed, should add up to 1. If a subset of objectives are listed, should add up to less | ||
| than 1, and remaining weight will be evenly distributed between the remaining objectives. Should not be used | ||
| at the same time as prioritized_objective. |
There was a problem hiding this comment.
It's my fault for doing this piecemeal - I blame being distracted - but perhaps we should consider an API where these two are put together and that the input is a dict of str:float. If there is one value, then perhaps that should be interpreted as the prioritized weight/obj.
There was a problem hiding this comment.
As we've discussed previously, I'm hesitant to completely remove the prioritized objective/weight API. I think the benefit of the simplicity outweighs the slightly larger API. That being said, after thinking about it more I would be open to removing the prioritized_weight argument, and just keeping prioritized_objective. That allows users to have an easy way to say "I care about this one more", and if they want to be more specific about the weights, there is still custom_weights to open up that opportunity. Thoughts?
Closes #4149