import kotlin.math.*
max(a,b)
min(a,b)
abs(a)
sqrt(a)
arr.max()
arr.min()
arr.average()
String.trim() : 문자열 양 끝 공백 제거 (가끔 백준 입력에 공백이 잘못 들어가 있는 경우 NumberFormatException 방지)
arr.maxOrNull()
arr.minOrNull()
arr.indexOf()
arr.lastIndexOf()
arr.sortWith(compareBy({it.name}, {it.price}))
arr.minBy { it.price }
arr.filter { it -> it > 0}.forEach{ e -> print("$it ") }
onEach : 각 요소를 람다식으로 처리한 후 컬렉션을 반환! 요소 수정 불가 (print등의 처리에 사용)
forEach,forEachIndexed : 각 요소를 람다식으로 처리, 요소 수정 가능
map, mapIndexed : 각 요소를 람다식으로 처리한 후 컬렉션을 반환! 요소를 복사하고 편집함(기존 리스트의 요소 영향 x,기존 컬렉션의 리스트를 수정한 리스트를 얻을 때 사용)
mapNotNull : Null을 제외하고 식을 적용해 새로운 컬렉션 반환
fold: 초기값과 정해진 식에 따라 처음요소부터 끝 요소에 적용하며 값을 생성
reduce: fold와 동일하지만 초기값을 사용하지 않음
foldRight, reduceRight: 오른쪽부터 시작
✅ 코테 문제 핵심 유형
//easy
1.시간 관련 문제 (최소 단위로 통일)
- 00:00 ~ 24:00이 조건이면 누적 합 혹은 00~24까지 완탐 가능한지 확인
2.스케줄 관련 문제
- 보통 pq 혹은 누적 합으로 가능
- 누적 합 안 되면 pq로
- 혹은 누적 합 O(N)으로 만 통과 가능한 문제도?
- 정렬 + stack/queue등의 자료 구조를 활용한 구현 문제도 있음 (programmers )
3. 기본 bfs
- 완전 기본까진 아니고 치즈, 빙산처럼 외곽에서 안에 있는 요소에 몇 번 접근하는지 등
- 이런 문제는 보통 가장자리는 비어있다는 조건이 있거나 없으면 가상의 벽을(행 +1, 열 +1)만들어서 bfs
4. 해시 문제
- 문자열 문제로 분류도 가능할듯
- name이 문자열로 주어지고 name에 대한 정보들을 가지고 풀어나가는 문제
- 보통 해시로 해당 name에 대한 정보를 저장한다
5. 정렬 커스텀 문제
- 여러 조건들 + 특이한 조건들로 순위 결정
- 정렬 커스텀하거나 아니면 조건들을 합쳐서 한 번에 정렬해도 되는 경우 있음 (네이버 2022 코테)
6. 문자열 문제
//hard
1. bfs + 파라메트릭
- (간선 개수, 노드 수, 가중치 값) 모두 클 때 의심
- 크루스칼, 프림, 다익으로 풀릴 수도 있음
2. 투 포인터 or 누적 합
- 연속된 값들의 합을 요구할 때
3. 시뮬레이션
- 배열 뒤집기 or 돌리기는 빡구현, 어느정도 템플릿화 해놓자
- bfs 혹은 dfs + 알파인 경우 많음
- 육각형 등
4. 트리
- 그래프 or 트리 탐색
- 간선을 뒤집어 제끼거나 뭐 하면 더 이상 이동할 수 없게 간선이 바뀌거나...
5. 조합 + 순열 플러스 알파 혹은 중복 조합 or 중복 순열
- ex 카블2022 양궁 문제
6. bfs 응용
- ex 양과 늑대, 벽 부수고 이동하기 등
- 뭘 달고 다님
- data class 만들어서 상태값 들고 댕기자
7. 탐색에서 n 작으면 비트마스킹 고려
✅ 우선순위 큐 시간 복잡도 : 삽입, 삭제 logN (힙 정렬 유지해야 함), 따라서 N개의 요소를 삽입하는 시간 복잡도는 NlogN
✅ Char to Int, etc..
val ch = '5'
// to ASCII
println(ch.code)
//to Int
println(ch.digitToInt())
//trick
println(ch-'0') // 아스키값 5(53) - 아스키값 0(48) == 5
✅ map()으로 원하는 프로퍼티만 가진 리스트 만들기
data class SiteVisit(
val path: String,
val duration: Double,
val os: OS
)
enum class OS {WINDOWS, LINUX, MAC, IOS, ANDROID}
val averageWindowsDuration = log
.filter { it.os == OS.WINDOWS } // List< SiteVisit >
.map(SiteVisit::duration) // List< Double >
.average()
println(averageWindowsDuration)
✅ 2차원 리스트 평탄화 후 조건에 맞는 개수 찾기
lateinit var graph: Array>
filter.flatMap { it.asIterable() }.count { it >= search }
✅ capitalize() deprecated in kotlin1.5
capitalize는 코틀린 1.5부터 deprecated되었다.
이는 replaceFirstChar 등 여러 방법으로 대체할 수 있는데,
기존에 capitalize 대신 확장함수 등을 이용하여 좀 더 목적이 분명하고 명확한 이름을 사용하는 것을 권장한다.
s.split(' ').joinToString(" ") { it.lowercase().replaceFirstChar { it.uppercase() } }
✅ fold, reduce
val list = listOf(1,2,3,4,5,6)
println(list.fold(4) { total, next -> total + next }) //4 + 1 + ... + 6 = 25
println(list.ford(1)) { total, next -> total * next}) // 1 * 1 * 2 * ... * 6 = 720
println(list.reduce { total, next -> total + next })
✅ 컬렉션 반복문 더 야무지게 쓰기
val arr = listOf(1,2,3)
val returnedList1 = list.onEach{ println(it) }// 콜렉션을 반환, element를 변경할 순 없고 어떠한 처리는 가능
val returnedList2 = list.map{it*2} //콜렉션을 반환, element 변경할 수 있음
list.forEach { print("$it ")}
list.forEachIndexed {idx, value -> println("$idx $value")}
✅ 배열 평탄화 (다차원 -> 단일 배열)
// flatmap으로
flatten() : 다차원 배열을 단일 배열로 생성
Array에만 사용 가능 (IntArray, Collection 사용 불가)
val arr1 = arrayOf(arrayOf(1,2,3), arrayOf(4,5,6))
println(arr1.flatten())
// [1,2,3,4,5,6]
✅ 체이닝 예시 (feat. 필터링)
체이닝 : 메소드들 연결
val fruits = arrayOf("banana", "avocado", "apple", "kiwi")
fruits
.filter {it.startsWith("a")}
.sortedBy { it }
.map {it.toUpperCase() }
.forEach {println(it)}
✅ dfs vs bfs (feat. String Result)
dfs라면 sb.append(next) dfs() sb.deleteCharAt(lastIdx) 로, StringBuilder의 이점을 살릴 수 있는데,bfs 같은 경우 sb.append(next) q.add(sb) sb.deleteCharAt(lastIdx) 이런 식으로 하게 되면 모두 같은 sb를 참조하게 되어 string값이 원하는 대로 나오지 않는다. 따라서 큐에 문자열을 삽입할 때마다 어차피 DeepCopy로 넣어주어야 하니 StringBuilder의 이점을 살릴 수 없어 그냥 String으로 한다 // q.add(StringBuilder(sb))
✅ String vs StringBuilder vs StringBuffer
String : 데이터 잘 안 바뀔 때 StringBuilder, StringBuffer : 데이터 자주 바뀔 때 StringBuilder : 스레드세이프 X StringBuffer : 스레드 세이프 O
✅ temp 없이 swap -> xor swap
X ← X XOR Y Y ← X XOR Y X ← X XOR Y
✅ Kotlin String.capitalize() : 첫 번째 문자 대문자화!
String.capitalize() returns a copy of this string having its first letter upper-cased.
class Solution {
fun solution(s: String): String {
return s.toLowerCase().split(" ").map {
it.capitalize()
}.joinToString(" ")
}
}
✅ 진수 변환 출력
println(10.toString(2)) // 10진수 10 -> 2
println(Integer.toHexString(100)) // 10진수 100 -> 16진수
println(Integer.toOctalString(100)) // 10진수 100 -> 8진수 144
println(Integer.toBinaryString(100))// 10진수 100 -> 2진수 01100100
✅ 0으로 채워서 자릿수 맞추기 -> String.format("%04d",num)
write("${String.format("%0${k+1}d", maxAns)}\n${String.format("%0${k+1}d", minAns)}")
✅ 두 개의 그래프를 비교하는 스킬
큰 그래프를 하나 두고, 가운데 하나 그래프 고정, 나머지 그래프를 한 칸씩 이동하면서 비교짠돌이 호석 : https://ongveloper.tistory.com/526
✅ 입력 템플릿
fun getIntGraph() = br.readLine().split(' ').map { it.toInt() }
✅ sortBy faster than sortWith
//sortWith
fun ArrayList.customSort() {
this.sortWith { a, b ->
when {
a.age < b.age -> -1
a.age == b.age -> 0
else -> 1
}
}
}
//sortBy
tree.sortedBy { it.age }
//thenBy
sortedNode.sortWith(compareByDescending { it.y }.thenBy { it.x })
✅ Deque를 이용하여 정렬 줄이기
//새로 값이 추가될 때 addFirst 혹은 addLast로 조절 가능
//값을 뺄 때도 pollFirst 혹은 pollLast
//https://www.acmicpc.net/problem/16235
val tree= ArrayDeque()
tree.sortBy{it.age} // 최초 한 번만 정렬 후 나머지는 addFirst, addLast등으로 정렬 유지
✅ double/float.NaN으로 실수 validation
✅ trim()으로 빈 문자열 찾기
https://kkh0977.tistory.com/709
var str_one = " he l lo"
var str_two = " "
println("str_one 문자열 빈값 확인 : "+str_one.trim().isEmpty()) // false
println("str_two 문자열 빈값 확인 : "+str_two.trim().isEmpty()) // true
✅ Java 커스텀 정렬
class Edge implements Comparable<'Edge'>{
public long dis;
public int from;
public int to;
Edge(long dis, int from, int to){
this.from = from;
this.dis = dis;
this.to = to;
}
@Override
public int compareTo(Edge edge) {
if(this.dis < edge.dis) {
return -1;
}
else if(this.dis > edge.dis) {
return 1;
}
return 0;
}
}
//간선 dis 기준 오름차순
Collections.sort(edge);
✅ swap -> a = b.also{b = a}
✅ 시간 관련 문제 dd:hh:mm:ss는 항상 단위 통일
✅비트마스킹
val a = 0b00000011
val b = 0b00001100
Integer.bitCount(a xor b) // 4
// a xor b == 15(0b00001111)
Integer.toBinaryString(num) //ex) 000111010
str.toInt(2)
✅foreach{}는 Collection에 유리 https://hwan-shell.tistory.com/245
✅배열 중복 값 제거 -> val newArr : List = arr.distinct()
✅indexOf는 O(N) -> set에서 요소 찾을 때 contains사용 O(1)
✅CharArray to String -> val str = String(chArr)
✅Long.MAX_VALUE = 10^18~~~
✅소수점 셋째 자리에서 반올림 후 둘째 자리까지 출력 : write(String.format("%.2f", round(answer*100) /100))
✅Kotlin 2차원 그래프 입력
val graph = Array(n){r->
val st = StringTokenizer(br.readLine())
IntArray(m){c->
val node = st.nextToken().toInt()
if(node ==2){
sr = r
sc = c
}
node
}
}
✅백준 메모리 초과 유형들
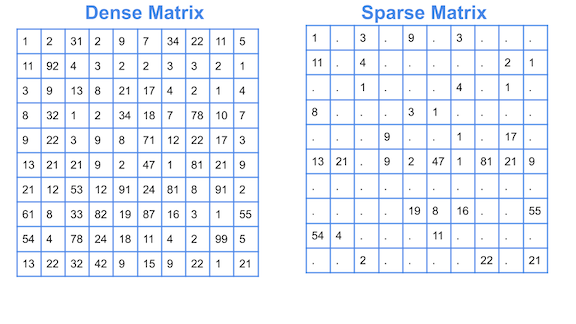
1.거대하고 sparse(드문드문한) 매트릭스 나올 때 2차원 배열로 할당할 시 //원본 배열은 큰데 실제 다루는 값이 드문드문하게 있는 경우 //쿠팡이나 아마존 모든 유저 장바구니에 담긴 상품 //카드 결제 내역 : 모든 음식점 x 사람별 카드 개수 //넷플릭스 영화 레이팅 : 무비전체 x 유저 전체 //내부 값은 드문드문하지만 이를 행렬로 관리하려면 전체 크기가 겁나게 커야 하니 //sparse 특성에 맞게 자료구조를 설계해야 함 //svd해서 역행렬 해서 그 값만 이용 블라블라
2.함수에 배열 통째로 넣었다가 터지는 경우(함수 파라미터로 크기가 큰 배열) 3.스택 큐 사이즈 점점 커질 때 (visited 체크 등 안 해서) 4. 깊이가 만 정도 이상의 재귀를 돌리면 스택에 함수 많이 들어가서 메모리 초과 5. 지역 변수 사이즈 커서 스택 영역 터지는 경우 6. 상태 저장하는 배열 동적 할당해서 엄청 커졌을 때 7. 슬라이딩 윈도우 문제 그냥 풀 때 8. 메모이제이션 안 해도 됐는데 메모이제이션 하다가
✅이분 탐색의 start는 배열 내에 인덱스, end는 배열 끝(바깥) 인덱스 (초기에는 start=0 end =arr.end())
✅최소 스패닝 트리를 만드는 크루스칼O(ElogE), 프림 알고리즘은O(ElogV), 간선이 많은 경우는 프림, 간선이 적은 경우는 크루스칼이 유리하다
✅조합 n 16까지, 순열 n 13정도까지
✅c++/ 조합 결과 출력 속도 순서 1.문자열 2. 배열 3.벡터
✅c++/ 배열 전역변수 선언 int arr[백만] 가능, 지역변수 선언 int arr[백만]터짐 int arr[십만]
✅set에 무언가를 저장하여 중복을 없애는 것보다 배열로 중복 없애는 게 빠름. ex(boj_21922_학부 연구생 민상)
✅크루스칼로는 안 되고 프림으로만 풀 수 있는 문제가 있다. 반대로 크루스칼은 프림으로 모두 풀 수 있다.
✅N>12이면 조합 안 쓰는게 좋음
✅it.first기준 내림차순, 같으면 it.seconde기준 오름차순 sortWith(compareBy {}.thenBy)
score.sortWith(compareByDescending> { it.first }.thenBy { it.second })
✅특정 문자열을 포함한 문자열들을 변형
val arr = Array(10){""}
arr.filter{it.contains("abc")}.forEach{it.replace("abc","ddd")}
✅ArrayList to Array
val strList = ArrayList()
val arr : Array = strList.toTypedArray()
✅깊은 복사와 얕은 복사
Kotlin에선 배열의 원본 아이템을 새로 만들어 새로 만드는 객체에 추가할 경우는 깊은 복사, 나머지는 얕은 복사이다. 얕은 복사 : 원본의 값이 바뀜 깊은 복사 : 원본의 값이 바뀌지 않음val arr = intArrayOf(1,2,3)//얕은 복사 val arrCopy = arr arrCopy[0]=5 // arr[0] ==5로 바뀜
//얕은 복사 val arrCopy = arr.copyOf() arrCopy[0]=5 //arr[0] ==5로 바뀜
//깊은 복사 val arrCopy = IntArray(3) for(i in arr.indices){ arrCopy[i] = arr[i] } arrCopy[0]=5 // arr[0]==1 안 바뀜
//얕은 복사 val src1 = arrayListOf(arrayOf("ICN", "A"), arrayOf("ICN", "B"), arrayOf("B", "ICN")) val copiedForEachAdd = ArrayList<Array>() src1.forEach { copiedForEachAdd.add(it) } // for each add copiedForEachAdd[0][0]="changed" //src1[0][0] == "ICN" 안 바뀜 src1.forEach{print(it.contentToString())} println()
//깊은 복사 val src2 = arrayListOf(arrayOf("ICN", "A"), arrayOf("ICN", "B"), arrayOf("B", "ICN")) val copiedForEachAddCopyOf = ArrayList<Array>() copiedForEachAddCopyOf[0][0]="changed" //src2[0][0] == "ICN" 안 바뀜 src2.forEach { copiedForEachAddCopyOf.add(it.copyOf()) }// for each add copy of src2.forEach{print(it.contentToString())}
✅val (from,to) = List(2){Integer.parseInt(tk.nextToken())}
//nextToken 없을 때까지 계속
✅PriorityQueue 정렬 커스텀
//다익스트라 사용 pq
data class Node(val dis: Int, val r: Int, val c: Int)
val pq = PriorityQueue(Comparator { a, b ->
when {
a.dis < b.dis -> -1
a.dis == b.dis -> 0
else -> 1
}
})
✅Collection 정렬 커스텀
//문자열의 길이 기준 오름차순, 길이가 같다면 사전순 오름차순
val set = mutableSetOf()
val resultSet = set.sortedWith(Comparator { a, b ->
when {
a.length < b.length -> -1
a.length == b.length -> when {
a < b -> -1
else -> 1
}
else -> 1
}
})
✅PriorityQueue 내림차순 선언 두 가지 방식
val pq1= PriorityQueue({a,b -> b-a})
val pq2 = PriorityQueue(Collections.reverseOrder())
✅ 55.coreceAtMost(60) //return 55
✅?.(세이프콜), !!(non-null 단정 기호)
fun main(){
var str1 : String? = null
println("str1.length = ${str1?.length}") //result : null
//?.(세이프콜) : 앞의 변수가 null일 시 뒤의 length를 실행하지 않고 null을 반환
//세이프콜을 사용하지 않으면 컴파일에러 발생
println("str1.length =${str1!!.length}") //npe발생
// !!(non-null 단정 기호) : 앞의 변수가 널이 아닐꺼라고 단정한다.
// !!사용시 컴파일 에러는 발생하지 않으나 npe 런타임에러 발생
val len = if(str1 !=null) str1.length else -1 //자동 형 변환을 통해 str1이 null이 아님이 확인되면 str은 non-null상태가 되며, str1.length를 사용할 수 있다.
val len = str1?.length ?: -1 //위의 식을 세이프콜과 엘비스 표현식으로 간결하게 변환
//str1?.length가 null이면 -1을 반환 null이 아니면 str1.length를 반환
}
✅kotlin 함수에서 파라미터는 모두 값이 변하지 않는 Immutable이다. (val이 생략된 형태)
✅kotlin 함수에서 배열을 매개 변수로 받았을 때
fun change(arr : MutableList){
arr[2]=30
}
fun main(){
val arr = MutableList(5,{0})
println(arr[2])
change(arr)
println(arr[2])
}
result
0
30
✅토큰의 끝까지 입력받기
val tk = StringTokenizer(readLIne())while(tk.hasMoreTokens()){
arr[i] = Integer.parseInt(tk.nextToken())
}
✅소수점 자르기
String.format("%.3f", cnt / n*100)✅for문의 index (자바와의 차이점)
//java code
int i;
for(i=0; i<5;i++){
}
System.out.println(i);
코틀린의 i는 for문 내부에서 관리하기 때문에
for문 바깥에서 사용할 수 없음
//kotlin
var i :Int
for(i in 0 until 5){
}
println(i)//error : i를 초기화할 것
✅다양한 모습의 버퍼
1.접기/펼치기(❤import도 필요 없으며 가장 간결하다 )
fun main() = with(System.`in`.bufferedReader()){
with(System.out.bufferedWriter()){
var t = Integer.parseInt(readLine())
for(i in 1..t){
var token = StringTokenizer(readLine())
write("Case #$i: ${Integer.parseInt(token.nextToken())+Integer.parseInt(token.nextToken())}\n")
}
flush()
close()
}
close()
}
2.접기/펼치기
import java.io.BufferedReader import java.io.InputStreamReader import java.io.BufferedWriter import java.io.OutputStreamWriter import java.util.StringTokenizer
fun main() = with(BufferedReader(InputStreamReader(System.in))){ with(BufferedWriter(OutputStreamWriter(System.out))){ var t = Integer.parseInt(readLine()) for(i in 1..t){ var token = StringTokenizer(readLine()) write("Case #$i: ${Integer.parseInt(token.nextToken())+Integer.parseInt(token.nextToken())}\n") } flush() close() } close() }
3.접기/펼치기
import java.io.BufferedReader
import java.io.InputStreamReader
import java.io.BufferedWriter
import java.io.OutputStreamWriter
import java.util.StringTokenizer
fun main(){
val br = BufferedReader(InputStreamReader(System.in))
val bw = BufferedWriter(OutputStreamWriter(System.out))
val t = Integer.parseInt(br.readLine())
for(i in 1 .. t){
val token = StringTokenizer(br.readLine())
bw.write("Case #$i: ${Integer.parseInt(token.nextToken())+Integer.parseInt(token.nextToken())}\n")
}
bw.flush()
bw.close()
br.close()
}
✅입출력 속도
BufferedReader/Writer faster than Scanner faster than readLine(),print()
✅버퍼 사용법
import java.io.BufferedReader
import java.io.BufferedWriter
import java.io.InputStreamReader
val br = BufferedReader(InputStreamReader(System.in)
val bw = BufferedWriter(OutputStreamReader(System.out)
BufferedReader, BufferedWriter 사용 후 항상 닫아주기
안 닫으면 버퍼에 남아 있음
br.close()
bw.close()
✅int형변환 속도
Integer.parseInt() faster than .toInt()
✅입력 분리
StringTokenizer faster than split
✅입력 분리 저장
val (a,b) = br.readLine().split(' ').map{Integer.parseInt(it)}val st = StringTokenizer(br.readLine())
val (a,b) = List(2) {st.nextToken().toInt()}