Reductions within neuron kernels #371
Description
Being able to perform reductions across neuron kernels would be very useful e.g. for calculating softmax values across the output layer of a classifier. This is currently annoying to implement in GeNN except by adding an additional layers of neurons to calculate the sum / reducing on the host - both of which add one or more timesteps of latency.
Implementing this sort of reduction in CUDA would 'traditionally' require shared memory and liberal application of __syncthreads but, for populations of < warp size output neurons (which, in the context of output classes, is not unreasonable), the following algorithm can be used to provide each neuron with the sum of some value held in a register across a N neuron population:
for (int i=1; i<N; i*=2) {
value += __shfl_xor_sync((1 << N) - 1, value, i);
}This reduces following this pattern (adds value from thread i to the value from the thread with increasing bit swapped):
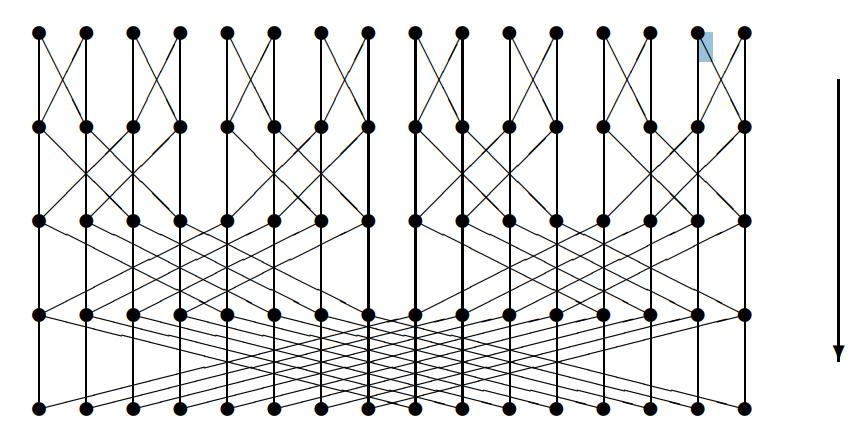
We could code generate unrolled versions of the above which could be inserted into code like this:
const scalar expY = exp($(Y));
scalar sumExpY = $(reduce_add, expY);
$(Pi) = expPi / sumExpPi;Min and max could also be implemented in a similar way to allow more numerically stable softmaxes to also be implemented and this approach could also be extended populations of up to block size by performing additional reductions via shared memory. However, it would still be rather a leaky abstraction as, not only is it dependent on warp/block size, but only works outside of any conditional code. Furthermore, there would be no obvious implementation for the single-threaded CPU backend. Nonetheless, I think it would be useful. Thoughts?